Initial concepts
So, what we can do with the Platform?
Register and login
First Steps - Creating your project
Profile
Permission System
Project Dashboard
Platform Glossary
Changing the Platform Language
2-Factor Authentication
Invalid authentication code
Artificial Intelligence
Human Attendance
Weni Chats: Introduction to the Chats module
Weni Chats: Human Service Dashboard
Weni Chats: Attendance distribution rule
Weni Chats: Using active triggering of flows
Using groups to organize human attendance
Studio
Contacts and Messages
Groups
Messages
Triggers and Campaigns
Adding a trigger
Triggers Types
Tell a flow to ignore triggers and keywords
Campaign introduction
How to create a Campaign
Editing events
Creating contact from an external Webhook
Contact history
How to Download and Extract Archived Data
Integrations
Settings
How to connect and talk to the bot through the settings
Adding a Facebook Channel
Adding a Viber channel
How to Create an SMS Channel - For Developers (RapidPro)
Web Chat Channel
General API concepts and Integrations
How to create a channel on twitter
How to create a channel on Instagram
How to create an SMS channel
Adding ticket creation fields in Zendesk
Adding Discord as a channel
Creating a Slack Channel
Adding a Viber channel (RapidPro)
Creating a Microsoft Teams channel
Weni Integrations
How to Use the Applications Module
How to Create a Web Channel
Adding a Telegram channel
How to create a channel with WhatsApp Demo
Whatsapp: Weni Express Integration
Whatsapp: How to create Template Messages
WhatsApp Template Messages: Impediments and Configurations
Supported Media Sending - WhatsApp Cloud
Zendesk - Human Support
Ticketer: Ticketer on Rapid Pro
Whatsapp Business API
Active message dispatch on WhatsApp
Whatsapp business API pricing
How to Verify My Business
Whatsapp Bussiness API: WhatsApp message triggering limitation
Regaining Access to Business Manager
Webhook Configuration: Message Delivery Status
The Basics of Integrations
Native ChatGPT Integration
Native Integration - VTEX
General settings
General Project Settings
Weni Chats: Setting Up Human Attendance
Weni Chats: Human Service Management
Flows
Expressions and Variables Introduction
Variables Glossary
Expressions Glossary
Flows Creation
Flows introduction
Flow editor and tools
Action cards
Zero Shot Learning
Decision cards
Adding Media to the message
Call Webhook: Making requests to external services
Import and export flows
Using expressions to capture the user's location
Viewing reports on the platform
Route markers
WhatsApp Message Card
UX Writing
Concepts
Good Practices for Chatbots Based on UX Writing
Hierarchy of information
Usability Heuristics for Chatbots
UX Text Standards
Weni CLI
- All Categories
- Artificial Intelligence
- Settings
Settings
Settings
In the Settings section of your Intelligence, you can manage various information, such as the name, description, main language, categories, whether the intelligence will be public or private, and, finally, the option to import/migrate your intelligence.
In this article, you will learn everything about these configuration options and how to use them!
General Information
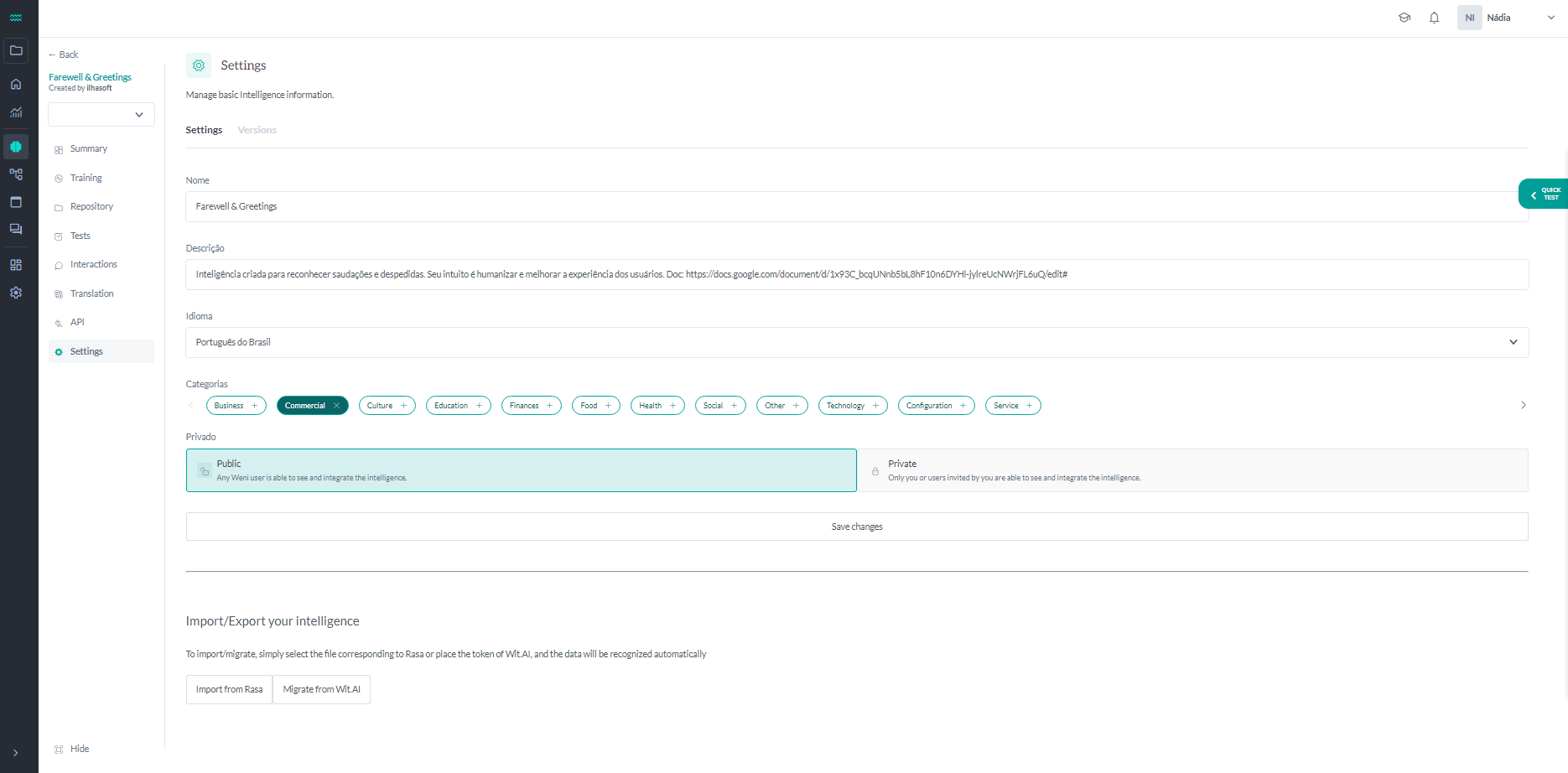
- Nome: This is how your intelligence is identified on the platform by the community. It is a good practice to name your intelligence in a way that makes its main objective and applications clear to other community users.
- Descrição: This is a brief summary of the intelligence, where you can explain its main functionalities and how it is built to other users. The description of the intelligence can be written in Markdown.
- Idioma: This is the default language of the intelligence. You can select any of the 45 languages available in Weni. Whenever you create a training or test phrase, this will be the language that appears first.
- Categorias: This is the classification of the intelligence by area of operation. Categories help other community users understand the scope and applications of the intelligence. For example, a bot with intents related to medical issues can be placed in the Health category. An intelligence can be classified into one or more categories.
Public Intelligence vs. Private Intelligence:
- Public: With this option, any Weni user can view and integrate this intelligence.
- Private: With this option, only you or invited users can view and integrate this intelligence.
Import Your Intelligence
To import/migrate, simply select the corresponding file for Rasa or provide the access token for Wit.AI, and the data will be recognized automatically.
- Import from Rasa: Only .TXT and .JSON files are accepted.
- Migrate from Wit.AI: Just add your Server Access Token and select the language.