Configurações
Na seção de Configurações da sua Inteligência, você pode gerenciar algumas informações, como nome, descrição, idioma principal, categorias, algoritmo de predição utilizado e opções de IA.
Nesse artigo, você aprenderá tudo sobre essas opções de configurações e como utilizar cada uma delas!
Informações Gerais
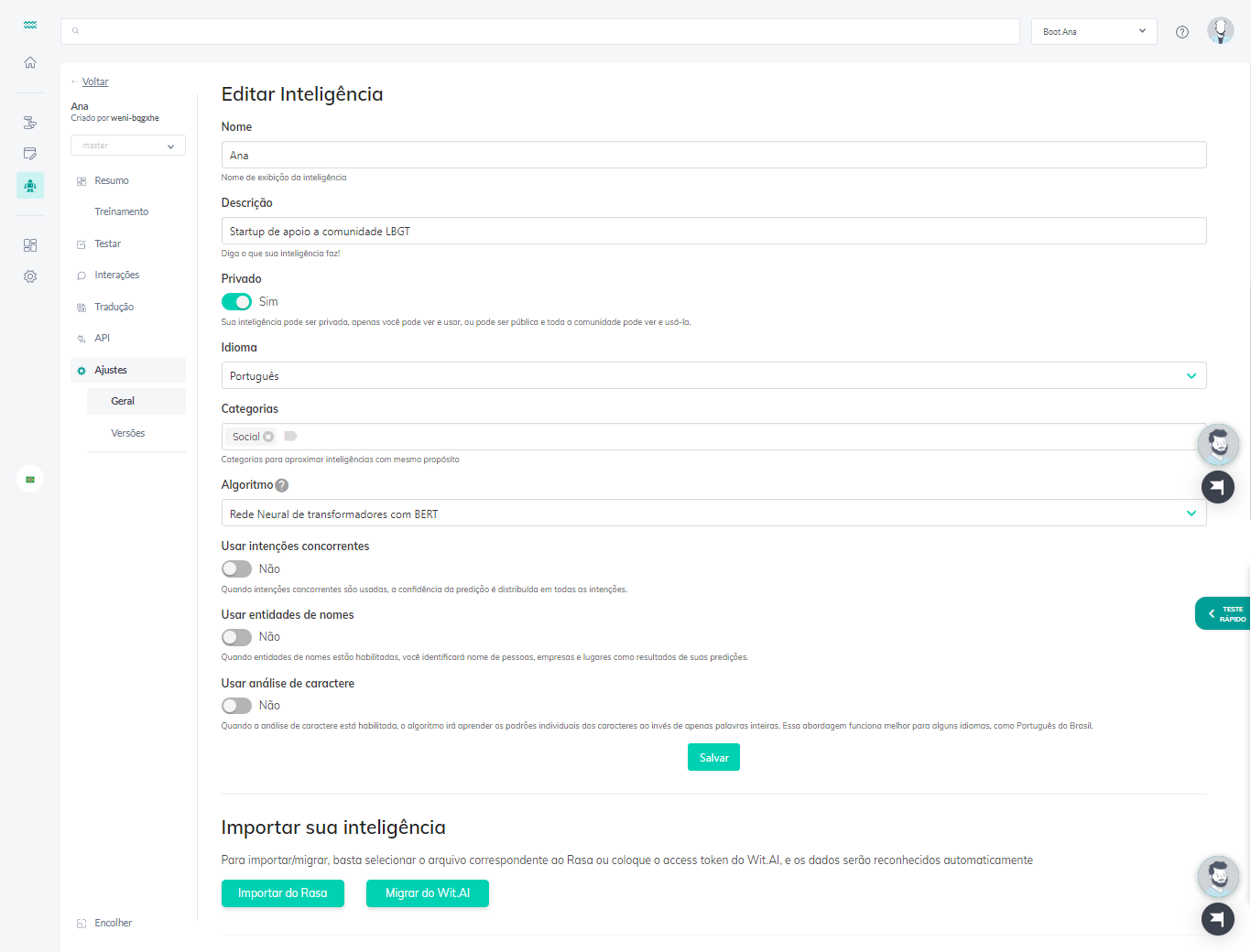
- Nome: É como sua inteligência é identificada na plataforma pela comunidade. É uma boa prática nomear sua inteligência de maneira que seu objetivo principal e aplicações fiquem claros para os outros usuários da comunidade.
- Descrição: É um breve resumo da inteligência, onde você pode explicar para outros usuários suas principais funcionalidades, e como ela é construída. A descrição da inteligência pode ser feita em Markdown.
- Idioma: É o idioma padrão da inteligência, você pode selecionar qualquer um dos 45 idiomas disponíveis na Weni. Sempre que você criar uma frase de treinamento ou teste, esse será o idioma que aparecerá primeiro.
- Categorias: É uma classificação da inteligência por área de atuação. As categorias ajudam outros usuários da comunidade a entender o escopo e aplicações da inteligência. Por exemplo, um bot que têm intenções relacionadas à problemas médicos pode ser colocado na categoria de Saúde. Uma inteligência pode ser classificada em uma ou mais categorias.
Algoritmos
Existem cinco tipos diferentes de algoritmos de predição na Weni. São eles:
- Redes Neurais com Vocabulário Interno
- Redes Neurais com Vocabulário Externo
- Redes Neurais de Transformadores com Vocabulário Interno (recomendado)
- Redes Neurais de Transformadores com Vocabulário Externo de palavras embarcadas
- Redes Neurais de Transformadores com BERT (recomendado)
Algoritmos com Vocabulário Interno (1, 3)
Esses algoritmos usam apenas o vocabulário no dataset de treinamento para realizar as classificações. Isso significa que a classificações será baseada apenas nas frases treinadas.
Uma das desvantagens desse método de treinamento é a necessidade que ele tem de uma grande quantidade de frases de treinamento para a predição ficar realmente assertiva.
É boa opção para ser utilizado em inteligências que tenham um contexto mais especifico.
Algoritmos com Vocabulário Externo (2, 4, 5)
Esses algoritmos, além de serem treinados com o conjunto de dados inserido pelo dono da inteligência, utilizam Word Embeddings, que são conjuntos de palavras pré-treinadas com o objetivo de inserir um contexto geral como base.
Esse contexto ajuda a relacionar palavras que nunca foram adicionadas no dataset, fazendo com que a inteligência tenha mais chances de direcionar uma frase nunca vista antes à sua intenção desejada.
Redes Neurais de Transformadores com BERT (5)
É o mais recente algoritmo da Weni que faz uso do conjunto de palavras pré-treinadas (vocabulário externo) do modelo estado da arte BERT (Bidirectional Encoder Representations from Transformers).
Atualmente está disponível para as linguagens PT-BR e EN.
Opções de IA
A Weni tem algumas opções de configuração de IA que ajudam sua inteligência a trabalhar de maneiras diferentes para objetivos diferentes! Abaixo, você pode encontrar quais são essas opções e como usá-las.
Competing Intents
A confiança da intenção pode ser exibida de duas formas. Nos próximos exemplos de imagens, usaremos a mesma sentença para o mesmo conjunto de dados, alterando apenas a opção de IA "Intenções Concorrentes" e ver as diferenças.
- Porcentagem por intenção

Classificação de intenção para a frase "Eu quero ir lá fora". Nesta opção (com Intenções concorrentes desativadas), a confiança para cada intenção é dada na proporção de 1: 1 (1 sentença, 1 confiança), isso significa, que o algoritmo apenas nos diz qual é a intenção de maior confiança. Podemos perceber que a soma de todas as confidencias para essa frase é mais do que 1.
- Todas as intenções Concorrentes
A confiança de uma sentença na configuração padrão (sem intenções concorrentes) é baseada na probabilidade percentual de cada intenção. Significa quanto a inteligência tem certeza de que a sentença é para cada intenção.
Quando você ativa esta opção, ela altera como a confiança é exibida na resposta JSON. Agora, a soma da confiança de todas as intenções é igual a 1 (100%), de modo que todos os resultados se complementam. Isso significa que o algoritmo mostra a intenção mais "dominante" para essa entrada de acordo com o conjunto de dados.
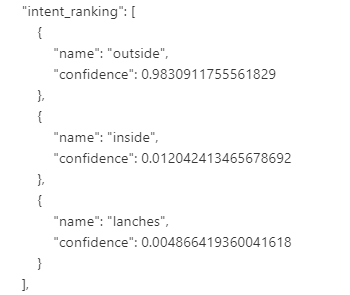
Dessa vez, notamos que a soma de todas as confidencias para a essa frase chega no máximo a 1.
Observe que esta opção altera apenas a forma como as informações de confiança são mostradas, mas não altera o funcionamento do algoritmo.
Name entities
É uma opção que usa um conjunto de dados pré-criado que identifica alguns nomes, lugares e empresas com um conjunto de dados externo. Ele os traz como entidades na resposta JSON.
Analyze char
Esta opção altera a maneira como o algoritmo processa as palavras. Quando o Analyze Char é ativado, o algoritmo quebra cada palavra em várias partes pequenas e aprende seu vocabulário com base nesses conjuntos de estruturas. Pode ter um bom resultado em idiomas onde as palavras têm muitas variações de si mesmas, como o português, por exemplo.
É recomendado que sejam feitos testes antes de ativar essa funcionalidade.