Testing your intelligence
Testing your intelligence
After adding several phrases for each intent in your created intelligence, you might want to know if your intelligence is working correctly, right?
To check if your training base is behaving as expected, you can use the Test section. This feature evaluates your range of information by executing the test base of training and comparing them.
Users can add test phrases, simulating final user inputs, to evaluate the quality of the training data or the selected algorithm. Since test phrases are different from the training phrases used to feed the intelligence, we can analyze, through some charts and metrics, how we can improve the training of the intelligence!
In this article, you will learn how to conduct a test in Weni and how to analyze its results.
Creating a test
To create a test, go to Tests -> Manuals in the intelligence you want to evaluate and add test phrases for each intent.
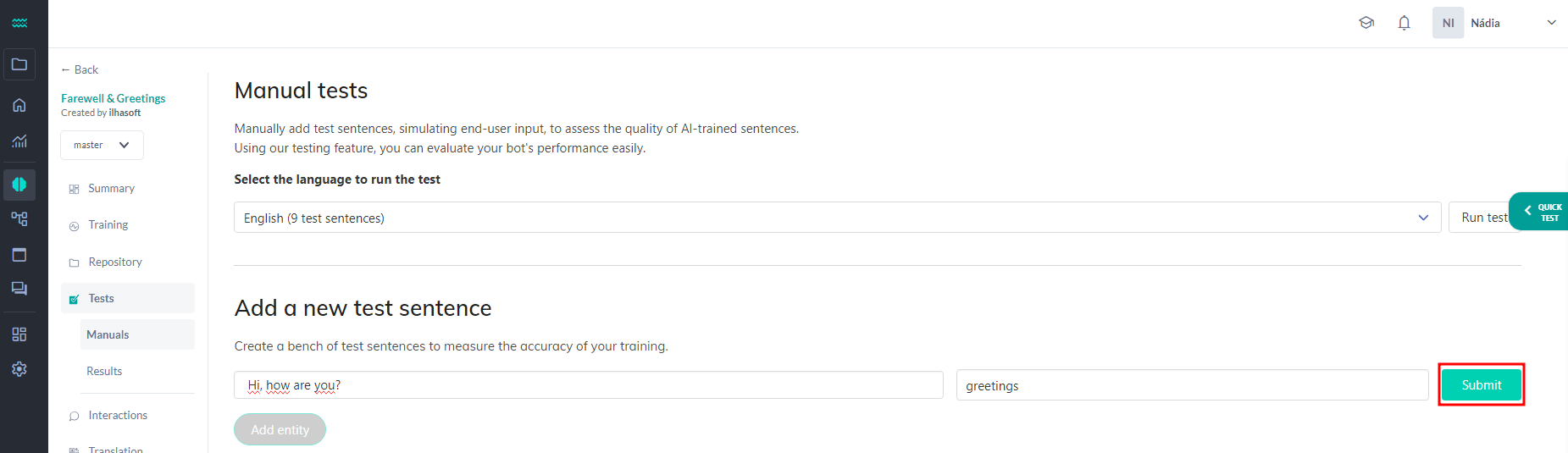
Once you have added the phrases to the test, select the desired language and click the Run Test button:

You will be redirected to the results screen, where all relevant test data will be displayed!
Results
In Tests -> Results, you can find all the test results previously conducted on this intelligence.
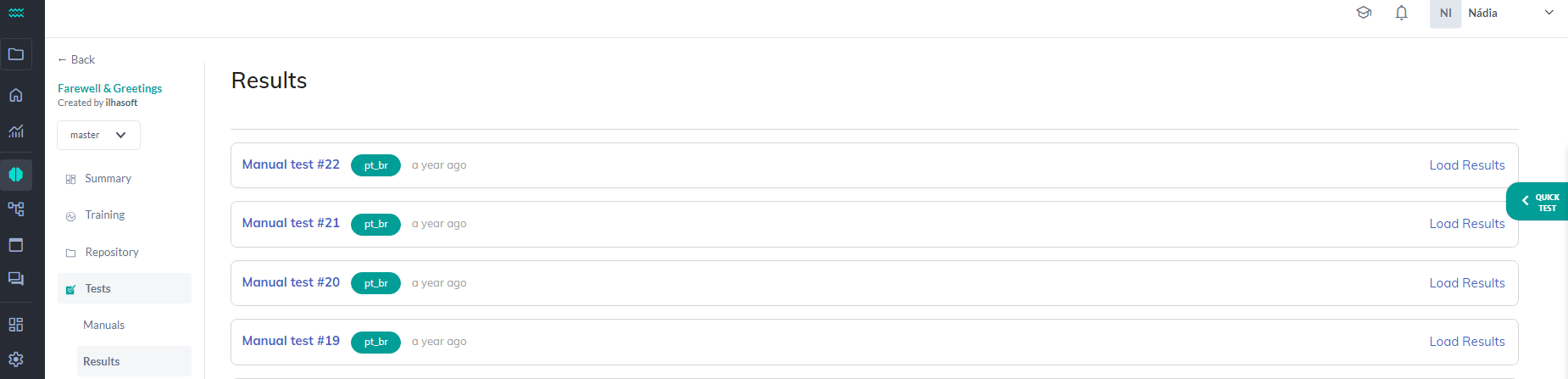
By selecting one of the listed results, some charts and metrics related to the chosen test will be displayed:
- Manual test
- Precision and recall reports
- Intent Confusion Matrix
- Intent confidence distribution
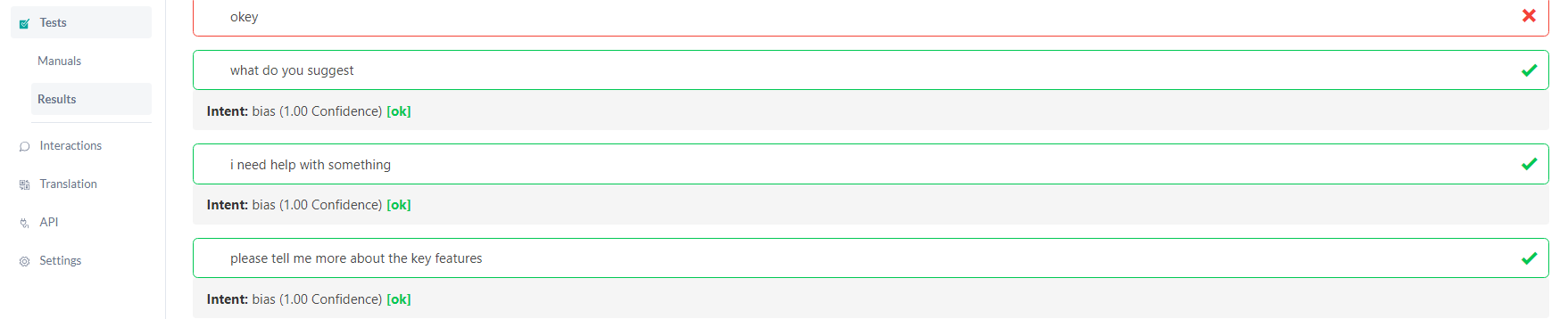
Manual test
It's a list of all the phrases tested by the algorithm and whether or not they were predicted correctly. Click on one of them to view the details about the test, such as the confidence and predicted intent for each phrase.
Precision and recall reports
A Precision score of 1.0 for intent X means that among the phrases classified as X, all actually belong to intent X (but it doesn't say anything about the remaining phrases of intent X that were not classified correctly).
A Recall of 1.0 means that among the phrases of intent X, all were correctly classified as X (but it doesn't say how many phrases from other intents were incorrectly classified as X).
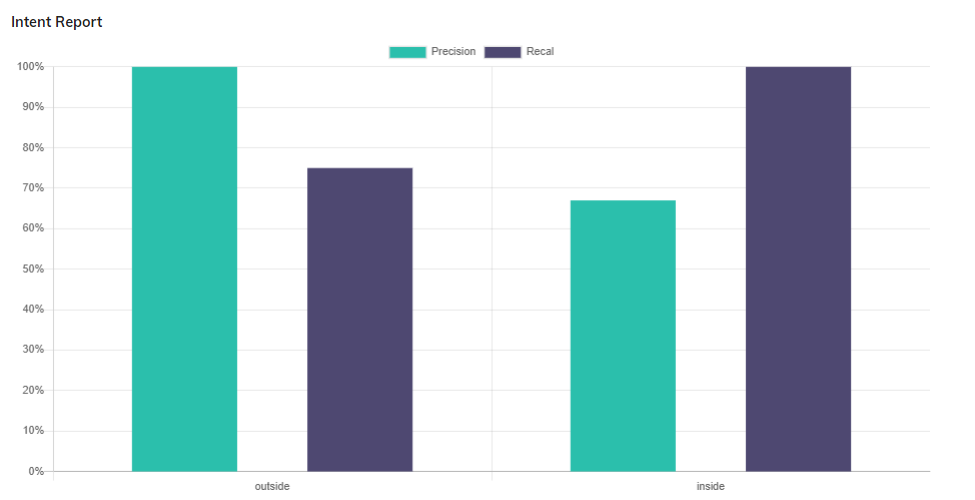
- Precision answers the following question: "In the set of all phrases classified as intent X (correct and incorrect), what proportion was correct?"
- An intent with no false positives has a Precision of 1.0.
- Recall answers the following question: "In the set of all phrases belonging to intent X, what proportion was classified correctly?"
- An intent with no false negatives has a Recall of 1.0.
- False positive and false negative, in the context of intent classification, as explained above, are:
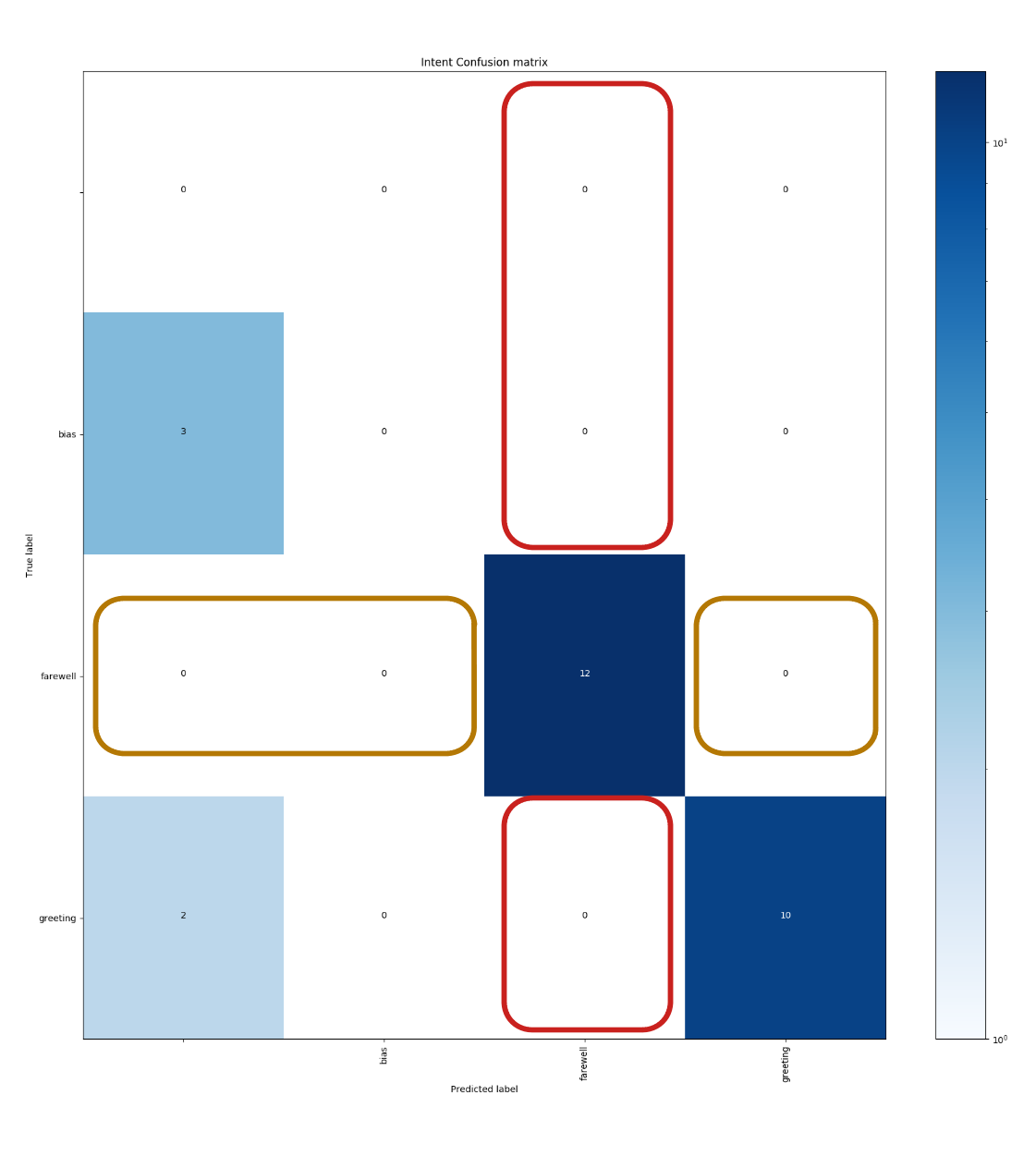
Intent confusion matrix
The confusion matrix shows which intents were confused with others. On the vertical axis, the intents that the intelligence should predict are listed, and on the horizontal axis are the intents that the intelligence actually predicted. In the confusion matrix, the ideal distribution of data should be diagonal, as this means all phrases were correctly predicted.
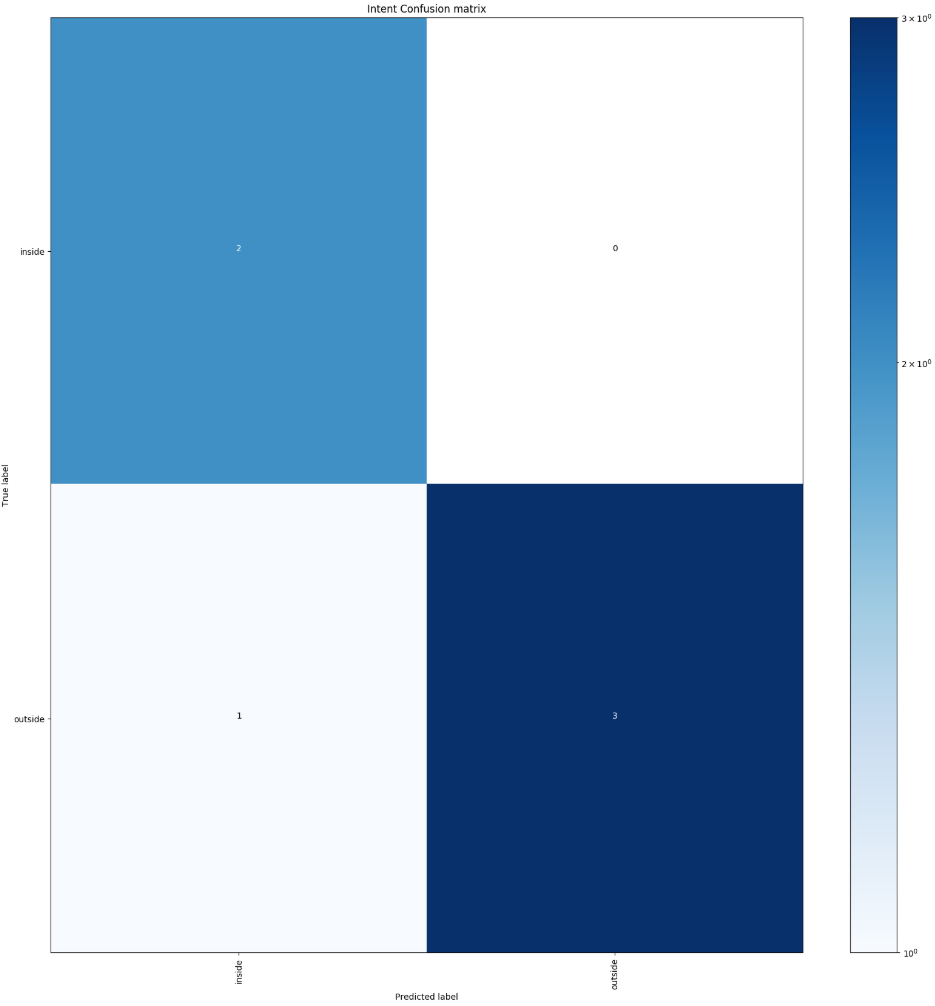
The matrix above shows us that one of the test sentences failed. The sentence has the intent outside, and was predicted by the algorithm as the intent inside.
Intent confidence distribution
The histogram allows visualization of the confidence distribution for all predictions made, with the number of correct and incorrect predictions shown in green and red bars, respectively.
Improving the quality of training will make the green bars move to the right and the red bars to the left, as ideally, incorrectly classified phrases should have a low classification confidence.
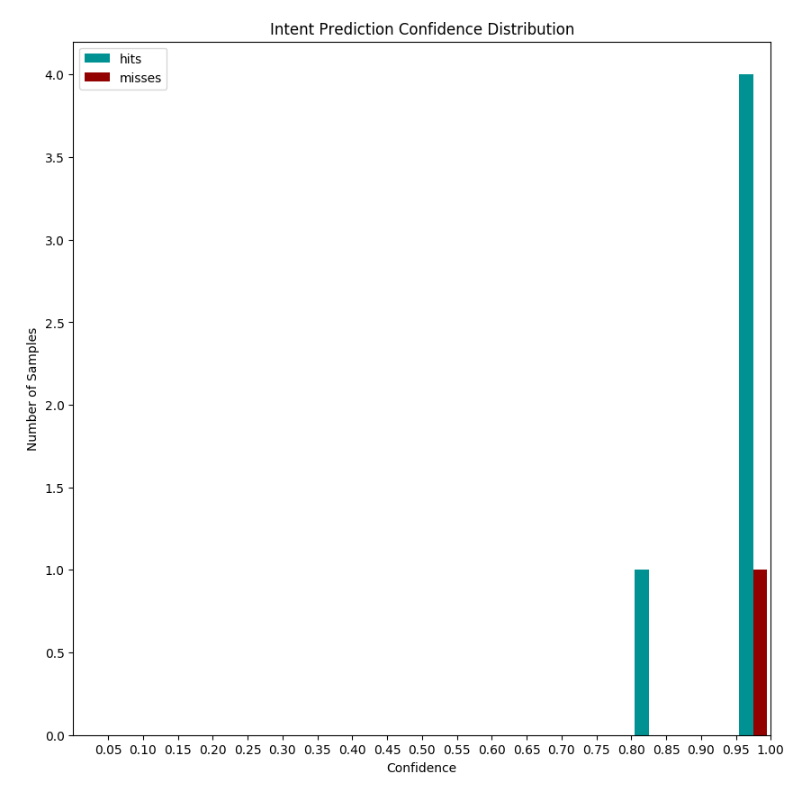
In the chart above, we can notice that most of the test sentences that were correctly predicted had 95% confidence, but some were classified with 100% confidence and were wrong, which is not a good sign.
Best practices
To get a better idea of whether your bot is truly intelligent, try adding real test phrases that the model has never seen before (phrases different from the trained ones). This will allow you to test whether your intelligence can truly abstract and understand the meaning of the trained intents to correctly classify a previously unseen test phrase.